Using NLP for examining entrepreneurs' business errors
I used natural language processing (NLP) to analyse texts entrepreneurs wrote about the errors that happened in their business over the past two weeks. Entrepreneurs in the sample were from India and the Netherlands, operating in various industries.
Data preparation
Loading standard libraries and source custom functions
library(kableExtra)
library(tidyverse)
library(expss)
library(lattice)
source("R/custom_functions.R")
Reading in data and preprocessing
I prepared the data for reliability assessment and correlation analysis.
dat <- read_csv("data/dat.csv")
evdes <- dat$t1evdes_
comp_dat <- dat %>%
dplyr::select(matches("t1emotions|jobstr|jobsa|t1threat|gender|age|found|t1occ$|lang|edu|max_sev"))
alph_dat <- dat %>%
dplyr::select(matches("t1emotions|jobstr|t1threat"))
comp_split <- comp_dat %>%
split.default(sub("_.*", "", names(comp_dat)))
alph_split <- alph_dat %>%
split.default(sub("_.*", "", names(alph_dat)))
comp <- map(comp_split, ~ multicon::composite(.x, nomiss = 0.8), data = .x) %>% as.data.frame(.)
alph <- map(alph_split, ~ psych::alpha(.x, check.keys=TRUE), data = .x) %>%
map(~ .x$total)
alph_df <- do.call("rbind", alph) %>% round(., 2)
Overview of sample characteristics
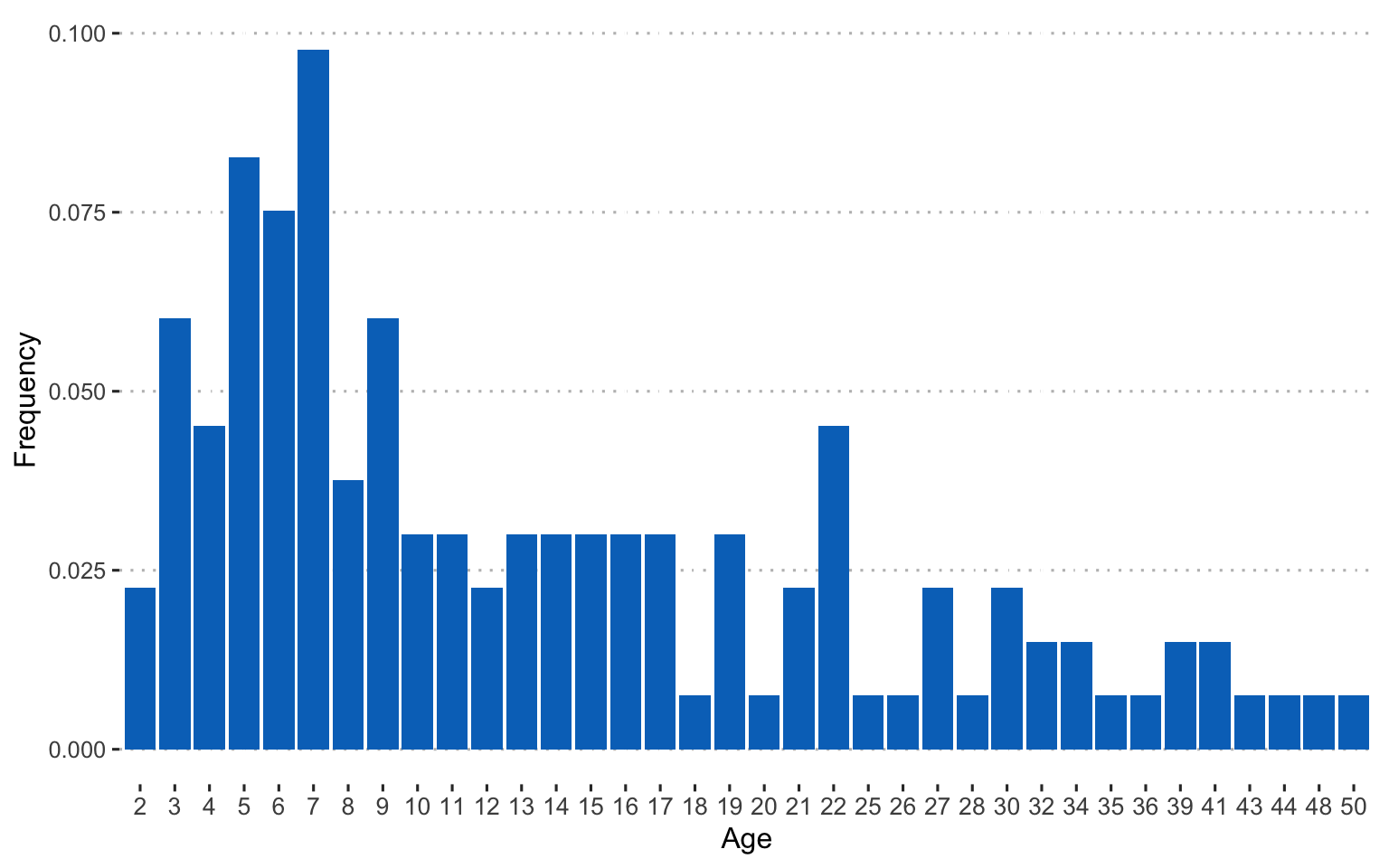
Age of the entrepreneurs in the sample:
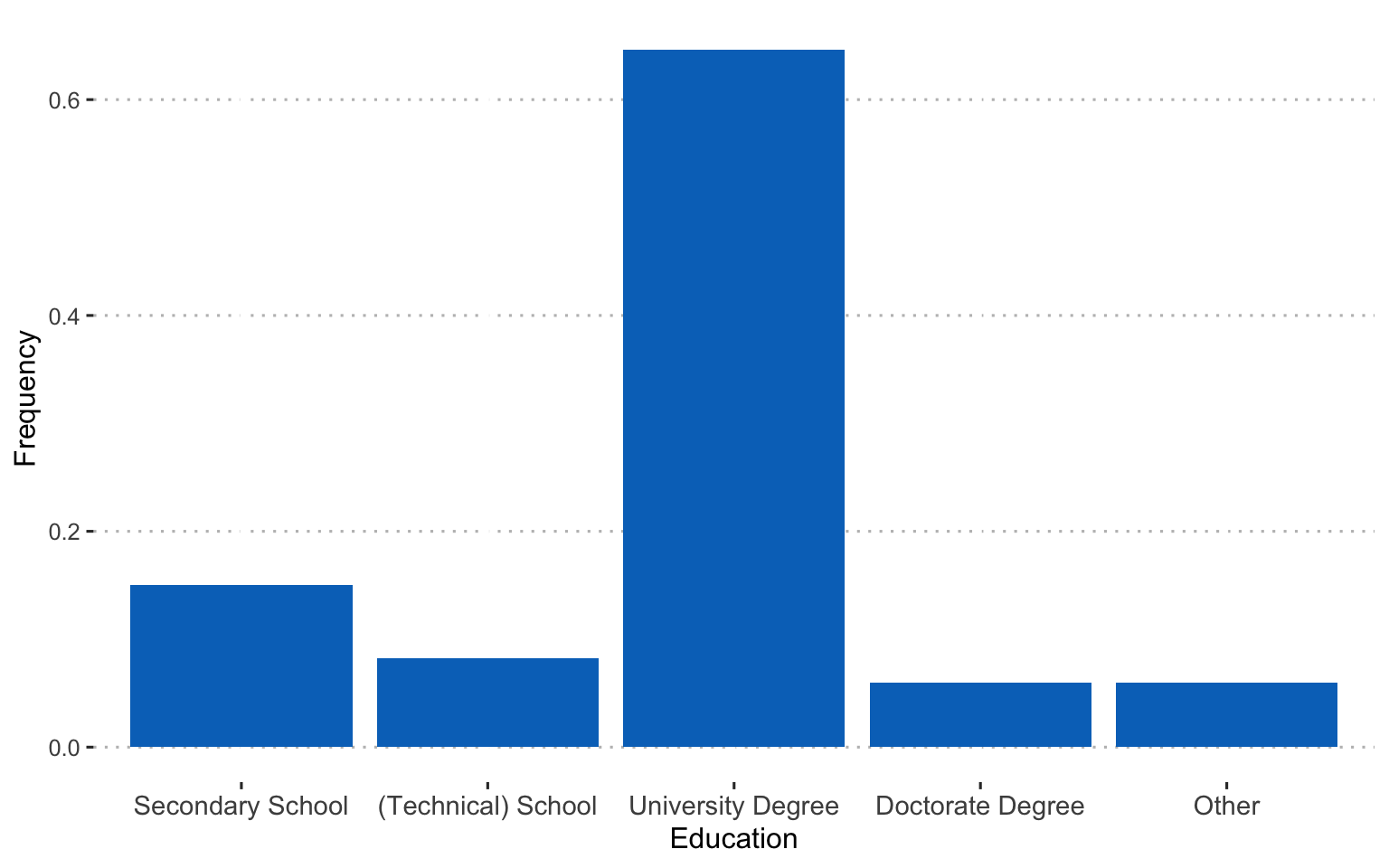
Educational level:
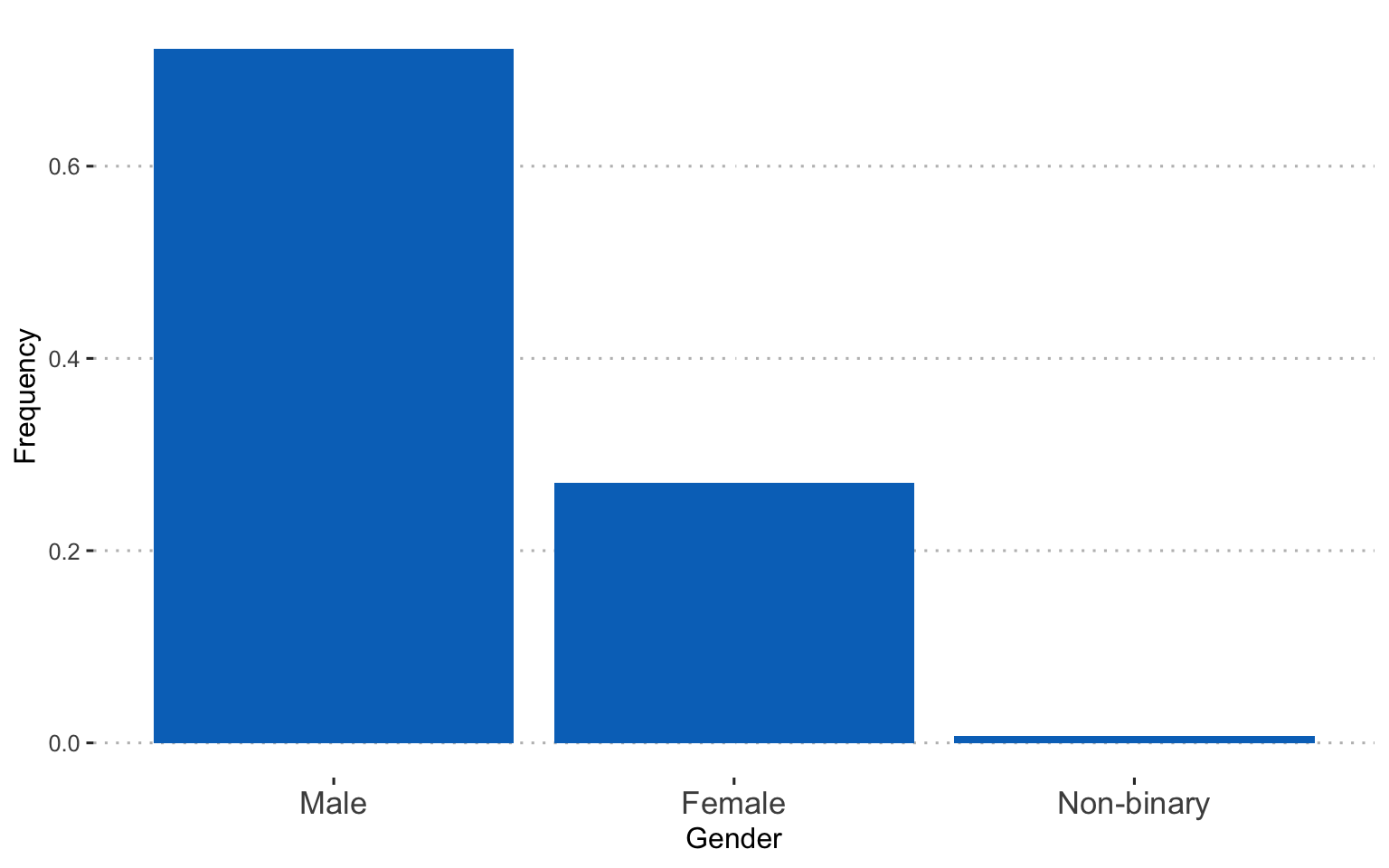
Gender:
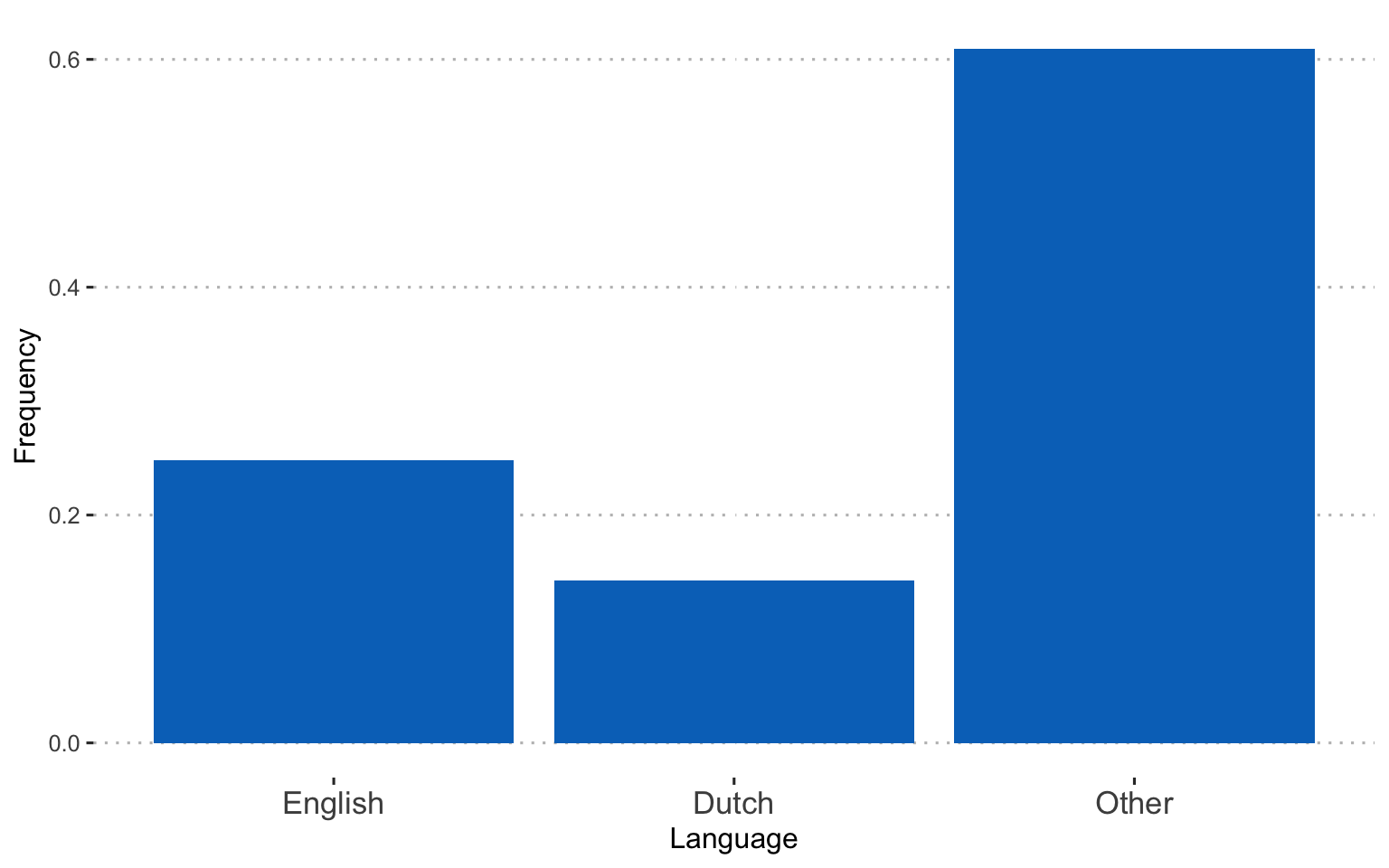
Language:
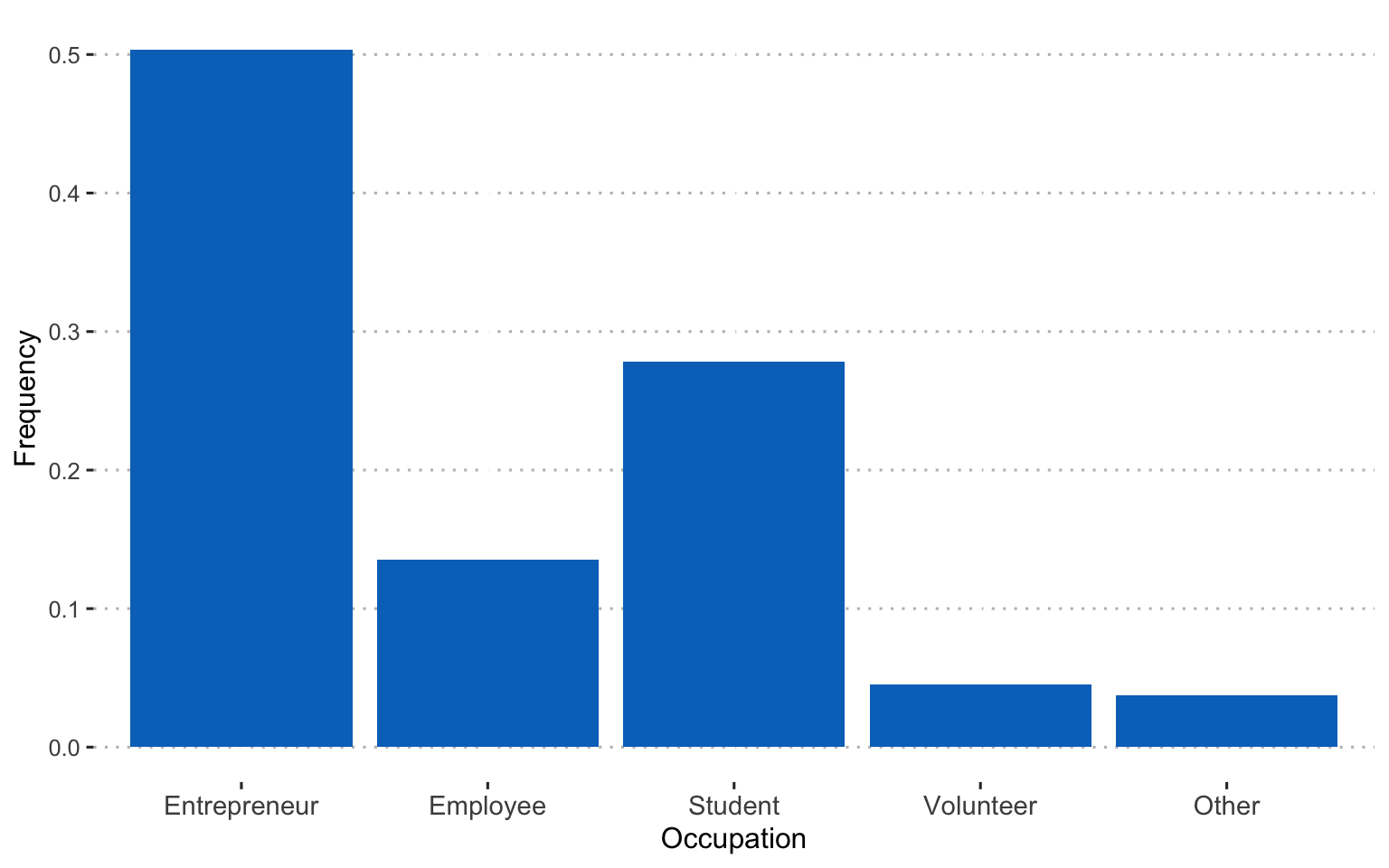
Current occupation:
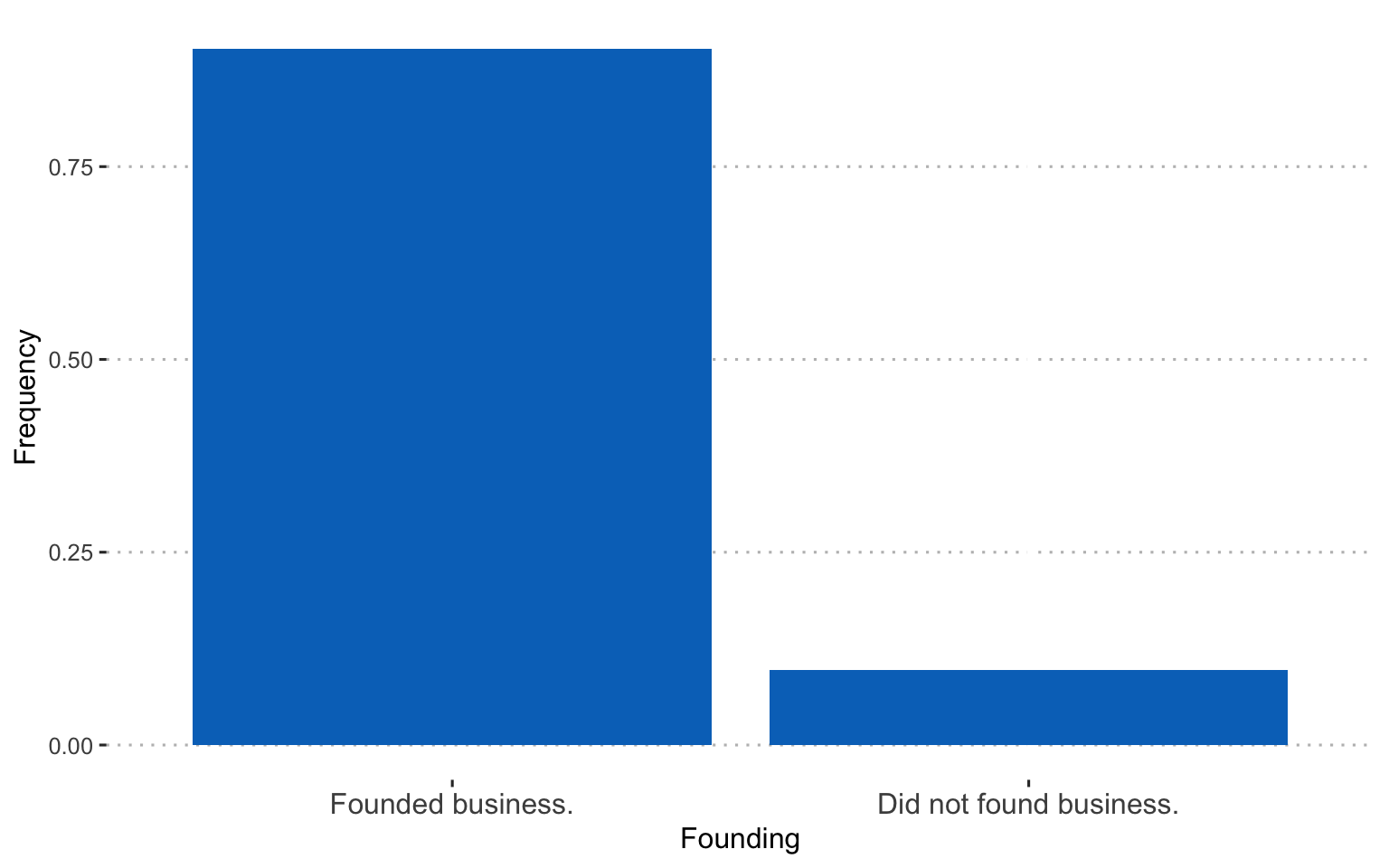
Whether they were involved in founding the business:
Reliabilities for multi-item variables:
alph_df %>%
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv"),
pageLength = 20))
Correlation table:
cor <- round(cor(comp, use="pairwise.complete.obs"), 2)
corstar_select <- data.frame(corstars(comp, removeTriangle = "none", result="none"))
corstar_select %>%
DT::datatable(
extensions = 'Buttons',
options = list(dom = 'Bfrtip',
buttons = c('excel', "csv"),
pageLength = 10,
lengthMenu = c(25, 50, 75, 94)))
Text mining
First, I created an annotated data frame from the text data.
library(udpipe)
ud_model <- udpipe_download_model(language = "english")
ud_model <- udpipe_load_model(ud_model$file_model)
x <- udpipe_annotate(ud_model, x = evdes)
x <- as.data.frame(x)
Next, I selected nouns and adjectives from the text data frame and removed duplicate entries.
library(tm)
stats <- subset(x, upos %in% c("NOUN", "ADJ"))
stats2 <- stats %>%
dplyr::group_by(doc_id) %>%
dplyr::mutate(sentences = paste0(token, collapse = " "))
evdes_nouns <- stats2[!(duplicated(stats2$sentences) | duplicated(stats2$sentences)),] %>% dplyr::select(sentences)
evdes <- evdes_nouns$sentences
evdes_1 <- VectorSource(evdes)
TextDoc <- Corpus(evdes_1)
Cleaning text data
I cleaned the data by removing unnecessary white space and converting special characters into white space. I also transformed all letters to lower case, removed numbers, stop words (e.g., and, or…), and punctuation. Finally, I lemmatized the remaining words (see here for more information on the lemmatization function.)
library(textstem)
#Replacing "/", "@" and "|" with space
toSpace <- content_transformer(function(x, pattern ) gsub(pattern, " ", x))
TextDoc <- tm_map(TextDoc, toSpace, "/")
TextDoc <- tm_map(TextDoc, toSpace, "@")
TextDoc <- tm_map(TextDoc, toSpace, "\\|")
TextDoc <- tm_map(TextDoc, toSpace, "\\|")
# Convert the text to lower case
TextDoc <- tm_map(TextDoc, content_transformer(tolower))
# Remove numbers
TextDoc <- tm_map(TextDoc, removeNumbers)
# Remove english common stopwords
TextDoc <- tm_map(TextDoc, removeWords, stopwords("english"))
# Remove punctuations
TextDoc <- tm_map(TextDoc, removePunctuation)
# Eliminate extra white spaces
TextDoc <- tm_map(TextDoc, stripWhitespace)
# Text stemming - which reduces words to their root form
#TextDoc <- tm_map(TextDoc, stemDocument)
TextDoc <- tm_map(TextDoc, lemmatize_strings)
Building the document martix
# Build a term-document matrix
TextDoc_tdm <- TermDocumentMatrix(TextDoc)
TextDoc_dtm <- DocumentTermMatrix(TextDoc)
TextDoc_tdm <- removeSparseTerms(TextDoc_tdm, .99)
TextDoc_dtm <- removeSparseTerms(TextDoc_dtm, .99)
dtm_m <- as.matrix(TextDoc_tdm)
# Sort by descearing value of frequency
dtm_v <- sort(rowSums(dtm_m),decreasing=TRUE)
dtm_d <- data.frame(word = names(dtm_v),freq=dtm_v)
# Display the top 5 most frequent words
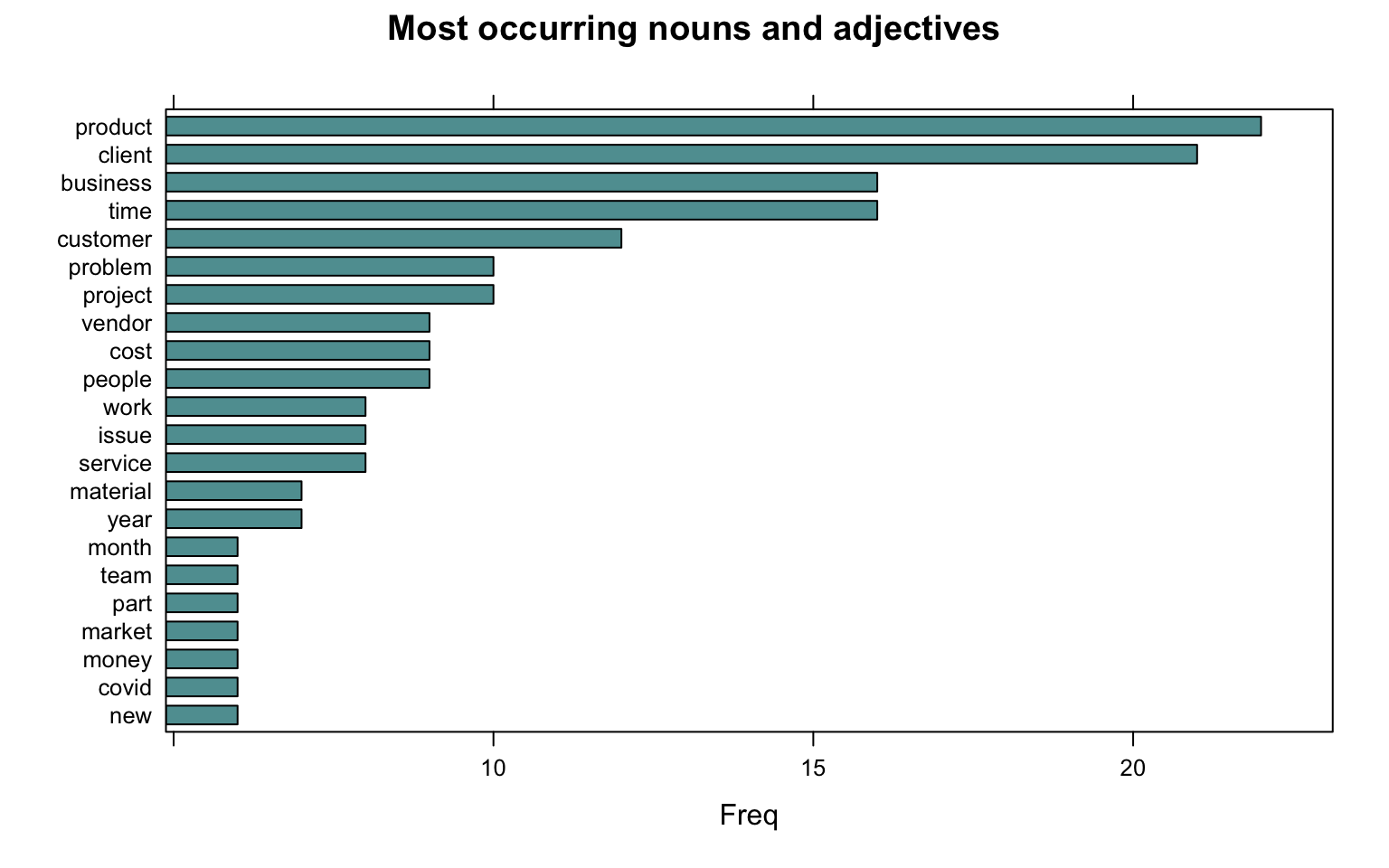
head(dtm_d, 5)
word freq
product product 22
client client 21
business business 16
time time 16
customer customer 12
A word cloud of the most common nouns and adjectives
library(wordcloud)
#generate word cloud
set.seed(1234)
wordcloud(words = dtm_d$word, freq = dtm_d$freq, min.freq = 5,
scale=c(3,.4),
max.words=100, random.order=FALSE, rot.per=0.40,
colors=brewer.pal(8, "Dark2"))
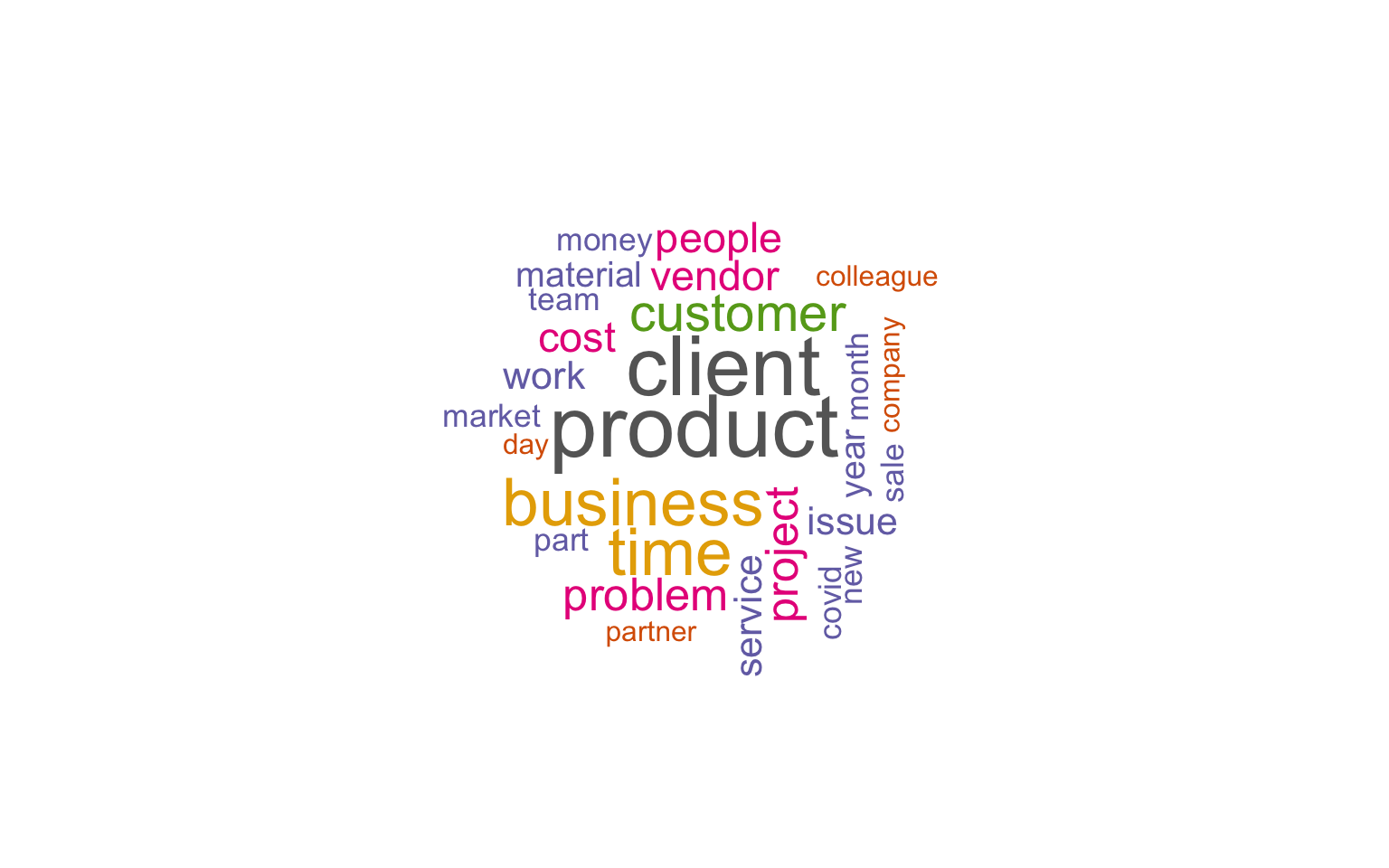
The most frequently occurring nouns and adjectives
stats <- subset(x, upos %in% c("NOUN", "ADJ"))
stats <- txt_freq(x = stats$lemma)
dtm_d$word <- factor(dtm_d$word, levels = rev(dtm_d$word))
dtm_head <- head(dtm_d, 22)
barchart(word ~ freq, data = dtm_head, col = "cadetblue", main = "Most occurring nouns and adjectives", xlab = "Freq")
Showing connections between words
I created a cluster dendogram to show connections between words.
library(tidytext)
dtm_top <- removeSparseTerms(TextDoc_tdm, sparse = .97)
TextDoc_tdm_m <- as.matrix(dtm_top)
distance <- dist(TextDoc_tdm_m, method = "euclidean")
fit <- hclust(distance, method = "complete")
plot(fit)
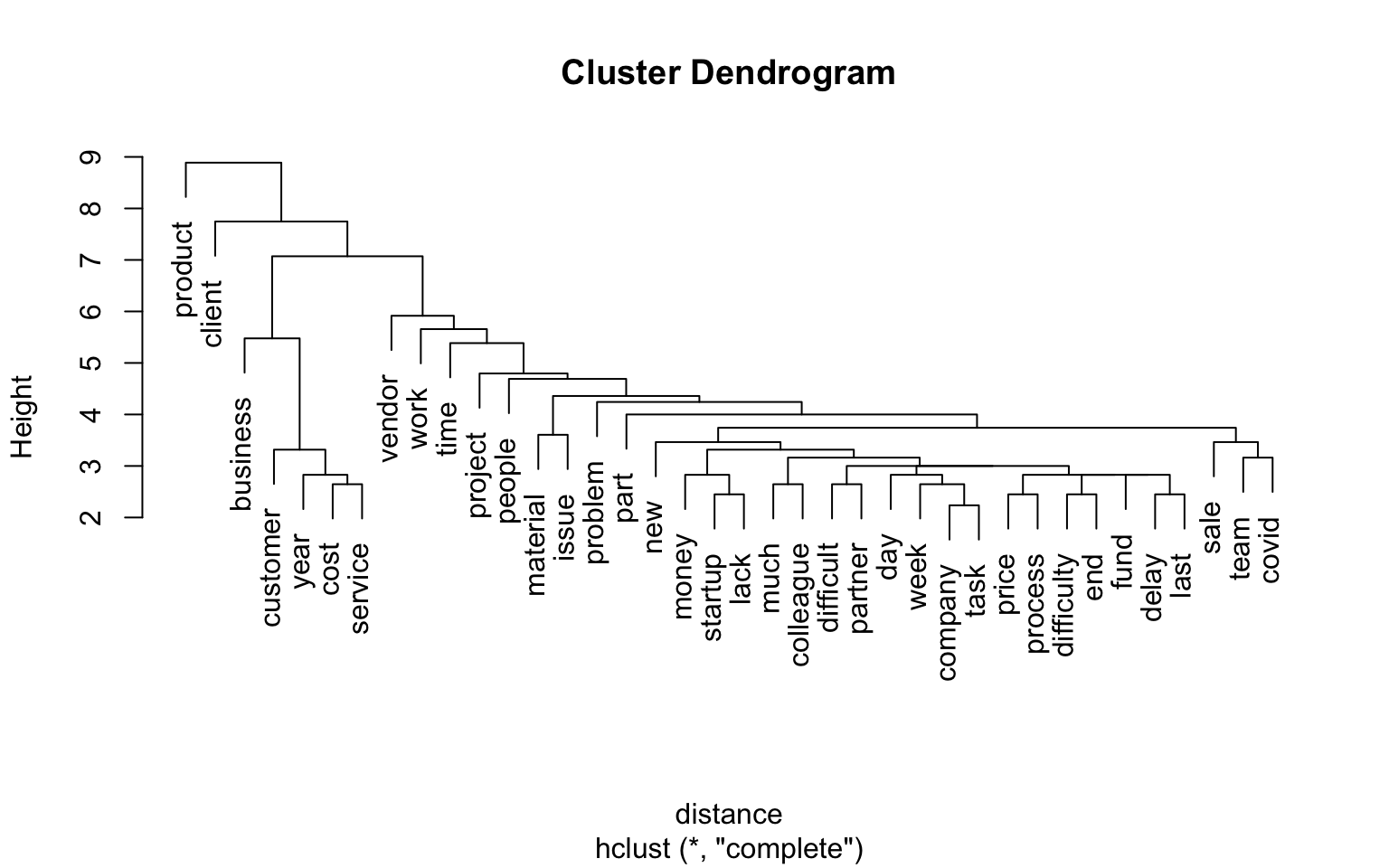
Hmm.. not super informative. What about trying to find topics in the texts?
Topic modeling
I started with 10 topics…
library(topicmodels)
rowTotals <- apply(TextDoc_dtm , 1, sum)
TextDoc_dtm <- TextDoc_dtm[rowTotals> 0, ]
# set a seed so that the output of the model is predictable
ap_lda <- LDA(TextDoc_dtm, k = 10, control = list(seed = 1234))
ap_lda
A LDA_VEM topic model with 10 topics.
#> A LDA_VEM topic model with 2 topics.
ap_topics <- tidy(ap_lda, matrix = "beta")
ap_top_terms <- ap_topics %>%
group_by(topic) %>%
slice_max(beta, n = 4) %>%
ungroup() %>%
arrange(topic, -beta)
ap_top_terms %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot(aes(beta, term, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
scale_y_reordered()
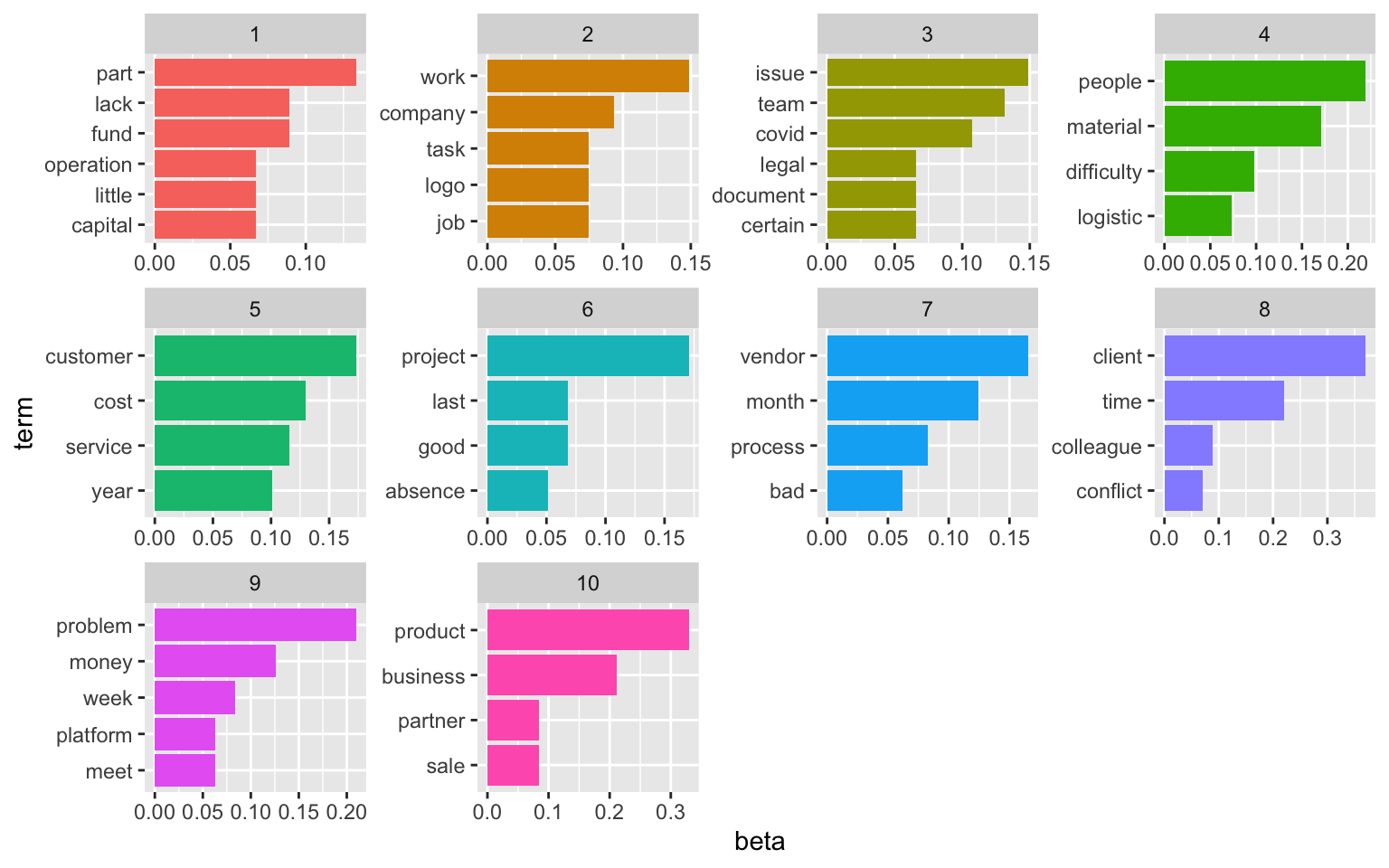
The visualisation displays the per-topic-per-word probabilities (called beta). For each word combination, the model computes the probability of that term being generated from that topic. For example, the most common words in topic 1 include “part”, “lack”, and “fund”. Maybe sth. related to capital and funding? Topic five revolves around issues with customers and service. The usefulness of the topic modeling always depends on the text data. And finding the right number of topics to extract is an iterative approach.
Here’s a solution for 6 topics:
# set a seed so that the output of the model is predictable
ap_lda <- LDA(TextDoc_dtm, k = 6, control = list(seed = 1234))
#> A LDA_VEM topic model with 2 topics.
ap_topics <- tidy(ap_lda, matrix = "beta")
ap_top_terms <- ap_topics %>%
group_by(topic) %>%
slice_max(beta, n = 5) %>%
ungroup() %>%
arrange(topic, -beta)
ap_top_terms %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot(aes(beta, term, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
scale_y_reordered()
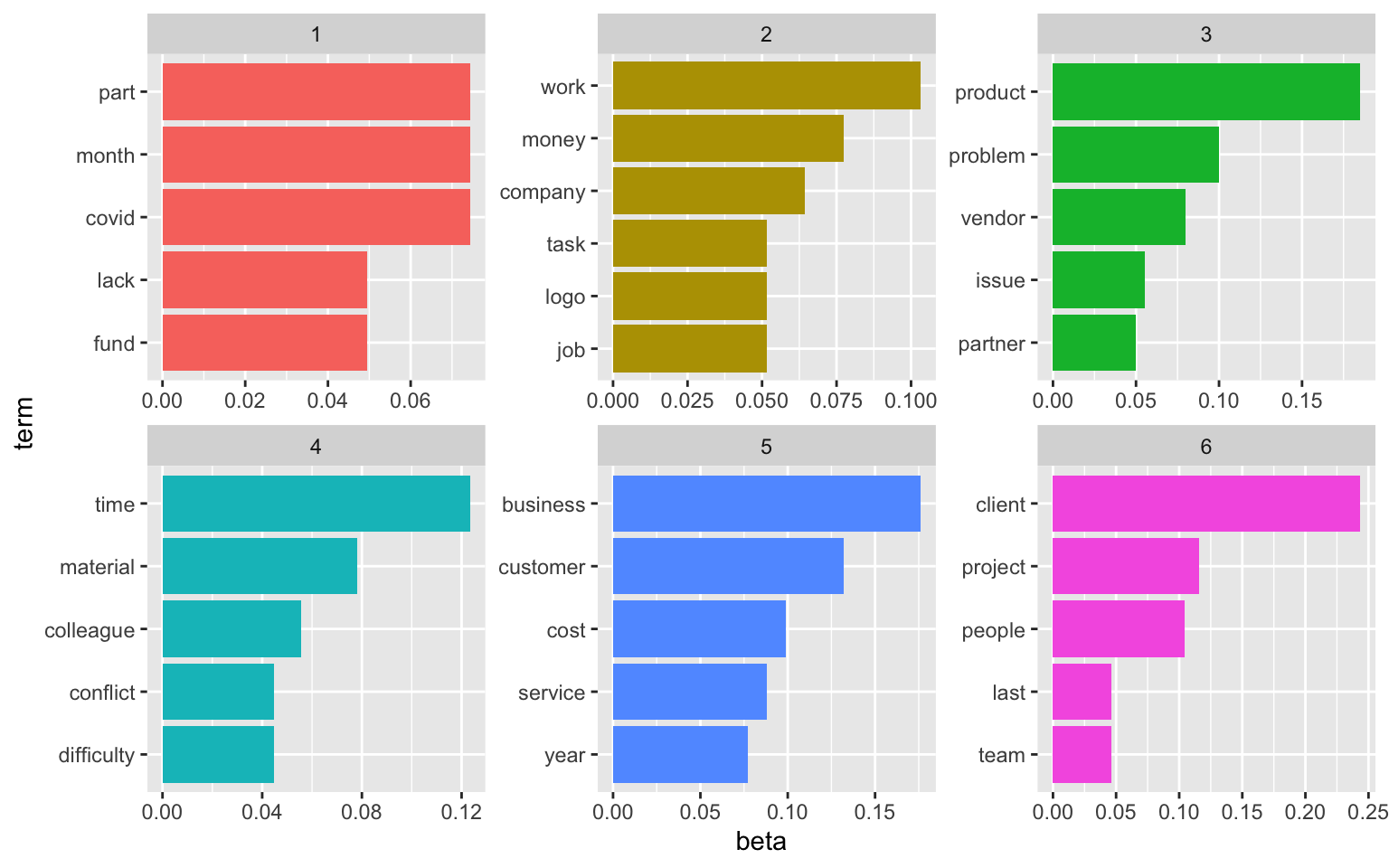
See here for more information on topic modeling.
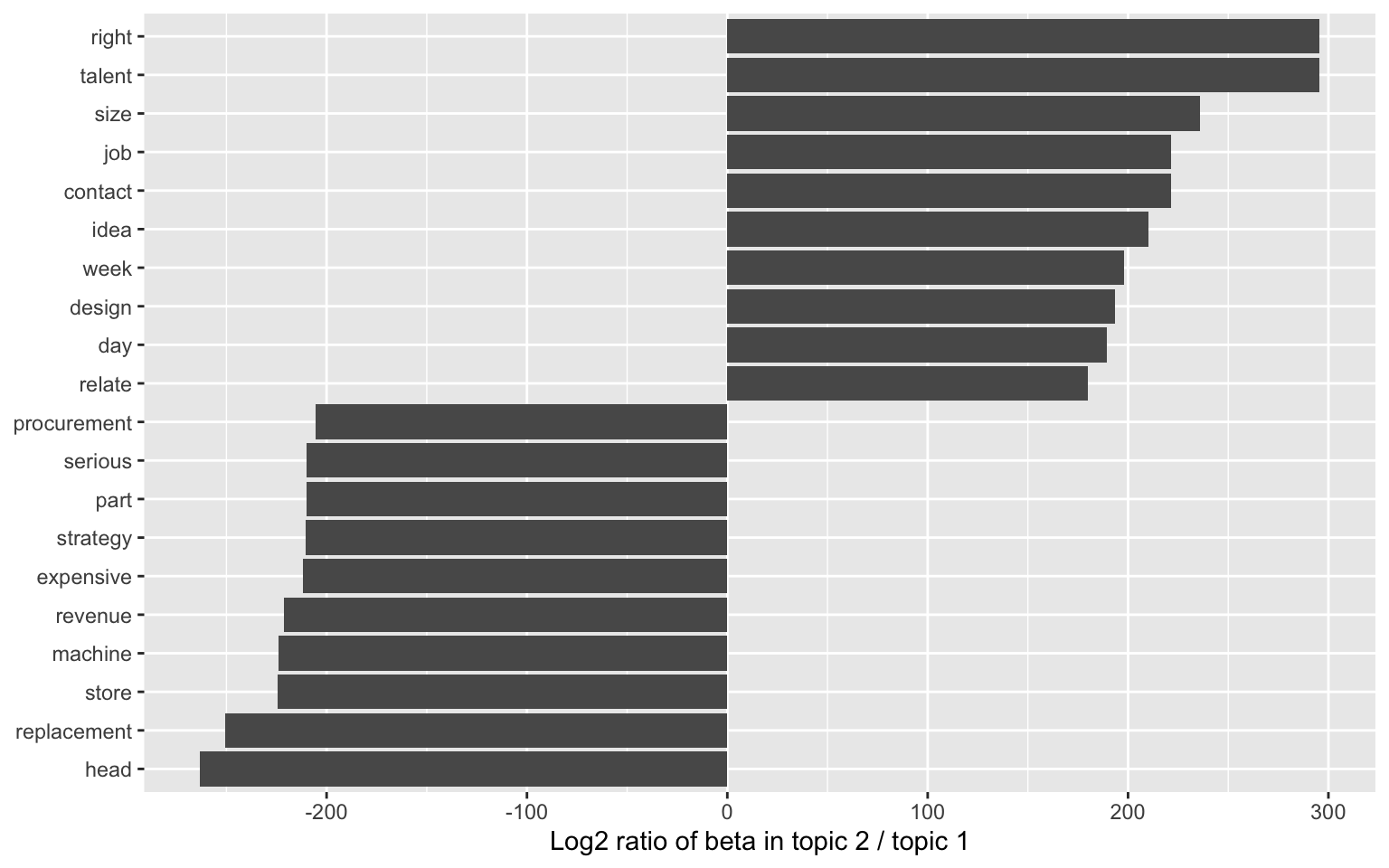
We could also consider examining the words with the greatest difference in beta between two topics. This can be estimated based on the log ratio of the two. We can filter for relatively common words to make the example more concrete. Here, we filter for words with a beta greater than 0.001.
library(tidyr)
beta_wide <- ap_topics %>%
mutate(topic = paste0("topic", topic)) %>%
pivot_wider(names_from = topic, values_from = beta) %>%
filter(topic1 > .001 | topic2 > .001) %>%
mutate(log_ratio = log2(topic2 / topic1))
beta_wide
# A tibble: 59 × 8
term topic1 topic2 topic3 topic4 topic5 topic6 log_ratio
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 financial 1.24e- 2 9.01e-60 2.00e- 2 7.09e-23 1.12e-13 4.47e-43 -190.
2 month 7.43e- 2 2.18e-29 1.92e-48 1.20e-78 1.14e-58 2.59e-45 -91.5
3 revenue 2.27e- 2 4.89e-69 1.78e-75 2.45e-63 1.29e- 2 3.24e-74 -221.
4 support 3.72e- 2 6.41e-25 3.27e-68 1.18e-21 3.88e-31 4.42e-25 -75.6
5 time 2.58e- 2 3.43e- 2 4.79e-14 1.23e- 1 8.13e-23 2.26e- 3 0.408
6 unable 2.48e- 2 6.61e-18 3.88e-28 4.38e-52 5.72e-10 1.53e-61 -51.7
7 company 4.81e-47 6.45e- 2 2.68e-42 3.58e-39 1.13e-71 2.67e-35 150.
8 contact 4.77e-69 2.58e- 2 1.33e-74 1.39e-71 3.81e-30 4.05e-71 222.
9 day 5.11e-59 5.02e- 2 1.01e- 2 4.96e-14 6.97e-36 1.15e- 3 189.
10 job 9.47e-69 5.16e- 2 3.06e-75 5.72e-71 2.03e-74 6.21e-25 222.
# … with 49 more rows
beta_wide %>%
group_by(direction = log_ratio > 0) %>%
slice_max(abs(log_ratio), n = 10) %>%
ungroup() %>%
mutate(term = reorder(term, log_ratio)) %>%
ggplot(aes(log_ratio, term)) +
geom_col() +
labs(x = "Log2 ratio of beta in topic 2 / topic 1", y = NULL)
- Posted on:
- January 1, 0001
- Length:
- 8 minute read, 1494 words
- See Also: